






2017/07/06
![]()
こんにちは。ビッグデータマガジンの廣野です。
「使ってみたくなる統計」シリーズ、第3回目はクラスター分析です。
前回まではデータ間の相関関係を発見する方法でしたが、このクラスター分析は目的が異なり、データ全体をグループ分けする方法です。データの見通しをよくする方法とも言えるでしょう。
巨大なデータを人間がていねいに目で見て傾向を読み解く、というのは(特にビッグなデータであれば)無理があります。このような時、データの傾向をもとに客観的にグループ分けしていけば、データの傾向や特徴が把握しやすくなります。場合によっては、事前にまったく想定していなかったような事実が発見できるかも知れません。
このようなメリットがあるため、クラスター分析はビッグデータが注目される前から、さまざまな領域で利用されてきました。
今回はこの便利な分析手法について、理解を深めていただければと思います。
■そもそもクラスター分析とは?
クラスター(cluster)とは「集団」「群れ」を意味する英語で、その名の通り、データ全体をいくつかの集団(グループ)に分類する分析手法です。一言で「クラスター分析」といっても、計算方法の違いで多くのバリエーションが存在します。ここではひとつひとつを詳しくは紹介しませんが、概要だけは理解しておきましょう。
クラスター分析は、グループ分けのための計算方法の違いで、大きく2つの方法に分類されます。
また、分類にあたっては、サンプル同士がお互いに「似ているか」(類似度:相関係数など)または「似ていないか」(非類似度:ユークリッド距離など)を基準に判断しています。この類似度・非類似度をもとにしたグループ分けの考え方の違いによって、多数のバリエーションが存在します(表1)。

表1 クラスター分析の代表的な手法
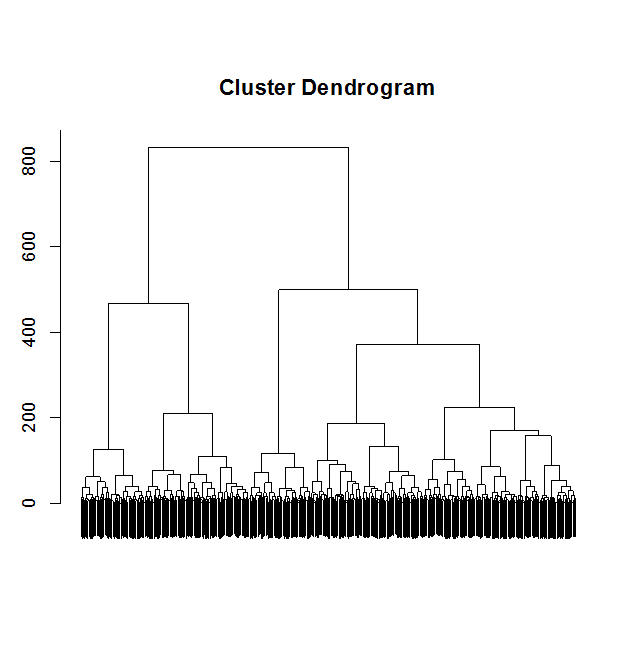
まず階層的手法ですが、全てのデータ間の類似度(または非類似度)を計算した後、ある基準で似たもの同士を併合していく方法です。たとえば図1は『最短距離法』と呼ばれる方法ですが、これはサンプル間の距離を非類似度として、最も近い(距離が短い)ものから順に同じクラスターとして併合していく方法です。
図1 最短距離法によるクラスタリングの例
ここでいう距離とは「ユークリッド距離」であり、高校の代数・幾何の授業で教わった「2点間の距離」と同じものです。(正確にはユークリッド平方距離)
距離が近いということはデータの傾向が近いということでもあるので、妥当な判断方法ではあるのですが、近い者同士が併合されてしまうと、同じクラスターに併合されるサンプル数が多くなるので、全体が“バランスよく”分類されなくなるデメリットもあります。
他にも、最も遠いものから順に併合していく『最長距離法』、各クラスターの重心からの距離をもとに併合していく『重心法』など、併合する際の判断基準の違いでさまざまな手法があります。当然、それぞれにメリット・デメリットがあるので、手持ちのデータの特徴・傾向と、欲しい分析結果を考慮して、適切な手法を選択することになります。
一般的には、判断に迷ったら『ウォード(Ward)法』を採用されることをお勧めします。『ウォード法』はクラスター内のデータの平方和を最小にするように考慮された方法ですが、データ全体が“バランスよく”分類されやすいため、よく使われる手法です。
また、併合されるプロセスが『デンドログラム』と呼ばれるトーナメント図のようなグラフで示されることも、階層的手法の特徴です。図2はR言語で作成したデンドログラムの例です。
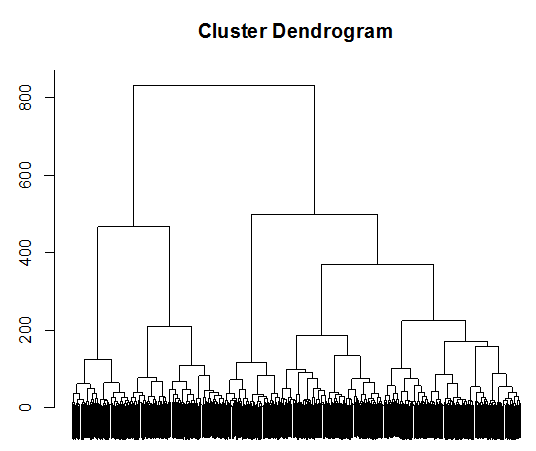
図2 階層的クラスター分析によるデンドログラムの例(R言語)
サンプル数が多いので文字がつぶれてしまっていますが、デンドログラムの並び順で近いところにいるサンプル同士は、データの傾向が似ており、似た者同士であるとみなすことができます。
『デンドログラム』をみれば、全体をいくつのクラスターに分割すればバランスが良いか、また、意味のある分類になりそうかを判断しやすくなりますので、分析結果を解釈する際の参考として有益です。
次に非階層的手法ですが、全体をあらかじめ決めておいたクラスター数に分割していく方法です。ここでは代表的な手法であるk平均法(k-means法)について解説します。
最初に、指定したクラスターの数だけ「重心」の位置をランダムに指定し、各重心からの距離をサンプルごとに計算します。重心からの距離が一番近いクラスターに所属させる判断基準で、まずは初期の所属クラスターを決定します。
次に、初期クラスターのなかで重心の位置を計算し直し、新しい重心の位置から各サンプルまでの距離を再掲計算します。そして、各重心からの距離の近さで、所属するクラスターを検討し直します。
このプロセスをクラスター間でのサンプルの再配置が起こらなくなるまで繰り返します。
階層的手法とは異なり、全サンプル間の距離を計算する必要はないため、計算量が軽くて済みますので、大規模なデータを分析する際に有効な方法です。
一方で、最初に指定する「重心」の位置はランダムに決められるため、同じデータで分析を行っているにも関わらず、分析結果(所属するクラスター)が微妙に変わることがあります。
分析プロセスの再現性が特に重要な場面では、あまりお勧めできない手法と言えます。
k-means法については、計算プロセスが分かりやすく紹介されているサイトがあるので、ぜひ一度ご覧ください。
(クラスタリングの定番アルゴリズム「K-means法」をビジュアライズしてみた
参考URL: http://tech.nitoyon.com/ja/blog/2009/04/09/kmeans-visualise/)
■ビジネスへの応用例
クラスター分析は大変応用範囲が広い分析手法ですが、ここでは代表的な使い方についての事例をご紹介します。
① ユーザーの特性に合わせた内容のダイレクトメール(DM)の配布
マーケティングへの応用例として最もポピュラーな使われ方で、現在でも利用されている“古くて新しい”やり方です。
クレジットカードやポイントカードのユーザー情報には、性別、年齢、住所、カード利用履歴などの有益な個人情報が蓄積されています。これらのデータを使ってクラスター分析を行い、ユーザーをさまざまな属性(性別、年齢など)や嗜好性、消費傾向を基準にしたいくつかのグループに分類します。(図3)

図3 クラスター分析による顧客のグループ分け
それぞれのグループ(クラスター)は異なるニーズを持っているため、そのニーズにマッチングした内容のDMを配布することで、カードの利用率の向上や、カードそのものの大会率の低下が期待できます。
② 複数の分析手法を組み合わせて商品レコメンドを実現(カーセンサーNET)
『カーセンサーNET』は月間アクセス数が750万人(2012年8月時点)で、国内最大級の中古車ポータルサイトです。
ここに蓄積される膨大な量のデータをもとに、車種選択画面で「同時に閲覧されることが多い車種」をレコメンドする機能が実装されていますが、その裏側でクラスター分析(クラスタリング)が活用されています。(図4)

図4 カーセンサーNETで実装しているクラスタリング+アソシエーション分析
(出典:ビッグデータの衝撃/城田真琴/東洋経済新報社)
あらかじめユーザーを性別・年齢などのクラスターに分類し、自動車も軽自動車・オープンカーなどのボディタイプ別にクラスター分けします。それぞれのクラスターに対してアソシエーション分析(第2回:アソシエーション分析を参照)を行い、レコメンドロジックを適用させています。この膨大で複雑な処理を行うために、分散処理技術であるHadoop(ハドゥープ)と、Hadoop上で動作するデータマイニングのライブラリであるMahout(マハウト)が活用されています。
■クラスター分析を活用する上での注意点
クラスター分析の結果、どれくらいの数にグループ分けするべきか?については、完全に分析者に委ねられています。グループ分けされた結果を解釈して、他者でも納得できるような意味を与えることは、クラスター分析の価値を大きく左右する重要なプロセスでもあります。分析したら終わり、ではないのです。
また、グループ分けした結果、データの見通しは良くなるのですが、そこからアクションにつながる示唆が得られるかどうかは別問題です。クラスター分析は分類までですので、分類されたサンプルの中で成立している法則性や、相関関係・因果関係までは分かりません。
このため、クラスター分析だけで業務改善等のアクションを検討するのではなく、分類された対象ごとに相関分析や回帰分析を行うことで、より精度の高い予測を実現し、アクションに繋げるような使われ方が多いことも、ぜひ覚えておいてください。
以上で、第3回目を終了します。
次回は「データの見通しをよくする分析手法」の続編として、主成分分析について紹介したいと思います。
【関連記事】 「使ってみたくなる統計」シリーズ
more
2017/07/06

2016/10/11

2016/08/04
more

2019/12/17

2018/08/17
more

2015/05/08

2014/11/06

2014/07/17
more
more

2018/07/04

2017/10/03
")
2017/03/30










![地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]](https://bdm.dga.co.jp/wp-content/uploads/2016/09/e9f52ed185c3179f4e6674d9459ffb02-250x150.jpg "地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]")






とは何か?")
をマーケティングに活かす! 〜AIは「読者の心をつかむ画像」を選定できるのか?〜")
をマーケティングに活かす! 〜AIでレコメンデーション・エンジンは賢くなるのか?〜")