





2017/07/06
![]()

こんにちは。ビッグデータマガジンの廣野です。
「使ってみたくなる統計」シリーズ、第4回目は主成分分析です。
前回のクラスター分析は、多数のデータを「グループ分け」して全体の見通しを良くする方法でしたが、主成分分析も似たような目的で利用します。多数のデータを「縮約」して、全体の見通しを良くするのです。
ビッグデータは“多変量”が当たり前ですから、たくさんのデータ項目(変数)を横断的に見て解釈することが求められます。このような時、情報の損失を最小限にしつつ、できるだけ少ない変数に置き換えて見ることができる主成分分析は、たいへん有効な手法と言えます。
ぜひ今回の記事で概要を理解していただき、皆さんの“データ分析の道具箱”に入れておいていただければと思います。
■そもそも主成分分析とは?
先ほど「縮約」と書きましたが、そもそも主成分分析は何をする手法なのでしょうか。
前回のクラスター分析は、大量のデータがあるときに、それぞれの距離を計算することでグループ分けをしていました。グループ分けすることで、個々のデータの特徴ではなく、グループごとの特徴を見ればよかったのです。変数の数が問題というよりも、データ数(サンプル数)が多いときに有効な手法でした。
主成分分析は、たくさんの変数があるときに、それをごく少数の(たいていは1~3の)項目に置き換えることで、データを解釈しやすくしてくれます。このような手続きを「次元の縮約」と呼びます。
具体的には、複数のデータ項目から新しい合成変数(軸)を生み出し、それを解釈することになります。
例として、2つの変数から新しい合成変数を生み出す方法を見てみましょう。
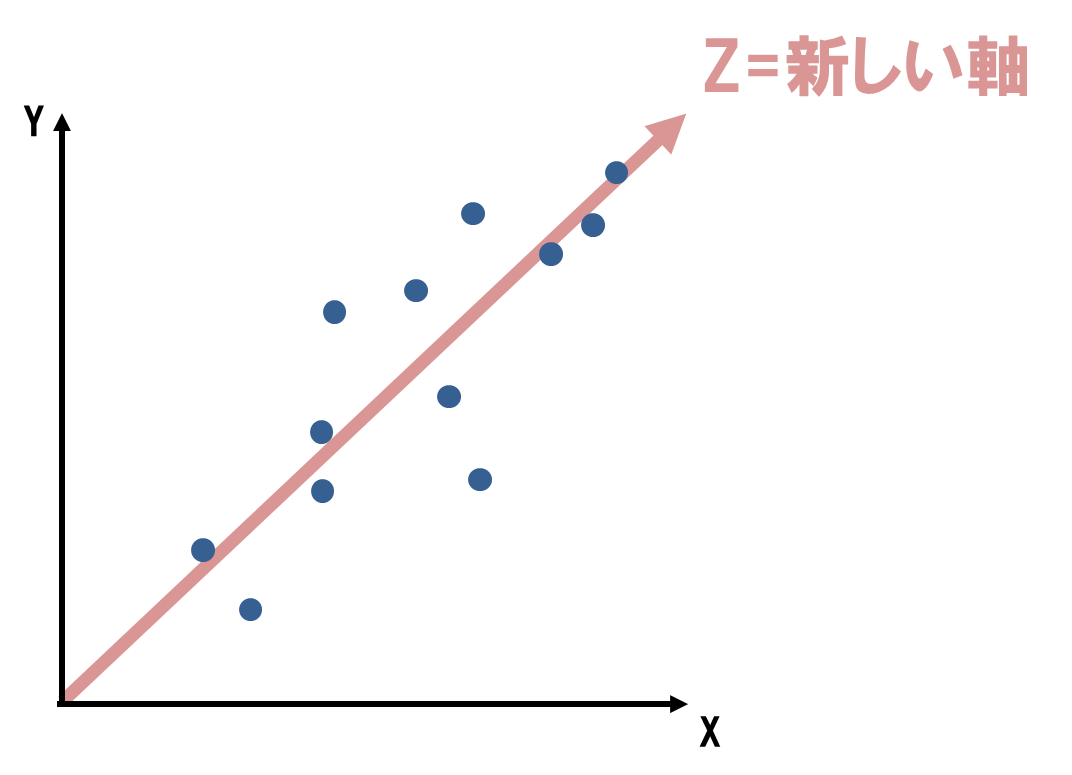
XとYという2つの変数があり、データが以下の図のように分布しているとします。
この2つの変数から、新しい合成変数Zを生み出すことで、全体の傾向が1つの変数を見れば理解できるようになります。
変数が2つだけだと有難みがイマイチ実感できませんが、変数の数が50、100・・・と増えていった時のことを想像すると、その効果が分かるのではないでしょうか。
もちろん、デメリットもあります。
この例で行くと、Z軸方向のデータのバラツキは分かりますが、Z軸と垂直方向のバラツキについては全く分かりません。
データが見やすくなった半面、一部の情報を捨ててしまっているのです。
捨ててしまった情報の中には、重要な意味が含まれているかも知れないので、できればこれも見られるようにしたいものです。
(図1-1 主成分分析の考え方)

(図1-2 主成分分析の考え方)
このような場合、主成分分析では、さらに別の合成変数(軸)を生み出すことで対応します。
2番目の合成変数(軸)は、上記の理由から、最初に作った合成変数とは直交(垂直に交差する)の関係になります。
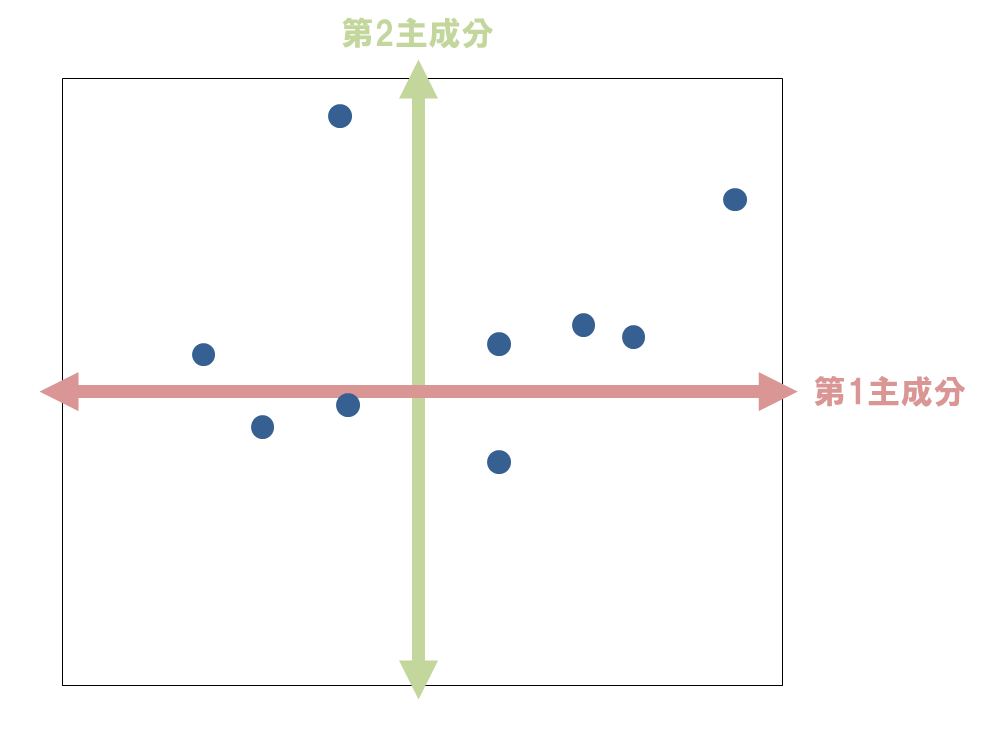
最初に生み出した合成変数(軸)を「第1主成分」、2番目に生み出した合成変数(軸)を「第2主成分」・・・と呼びます。「第1主成分」だけでなく「第2主成分」、「第3主成分」などを組み合わせて散布図を作成し、分析結果を解釈するのが一般的です。

(図1-3 主成分分析の考え方)
さて、これらの「主成分」は、どのようなルールで決めているのでしょうか。また、分析結果(アウトプット)はどのように与えられるのでしょうか。
「主成分」(合成変数)を決めるルールでは、情報の損失に着目します。ここでは、多くの情報を持つことを分散(データのバラツキ)の大きさで判断します。
分散が大きいということは、それだけ個々のデータを識別できていることでもあります。分散が大きい軸は、すなわち個々のデータについて多くの情報を有している、とみなすことができるわけです。
具体的な計算プロセスでは、相関係数を用いています。(相関係数については、以前の記事をご参考にしてください)
【関連記事】
第1回:相関分析(https://bdm.dga.co.jp/?p=1254)
2変数の相関係数が高くなると、データの分布は右肩上がり(または右肩下がり)にきれいに並び、相関係数が1(または-1)の時には、一直線上にすべてのデータが並びます。この性質を言い換えると、相関係数が高いと情報の損失(直交する方向のバラツキ)が少なくなる、とも言えるのです。
主成分分析では相関係数そのものではなく「固有ベクトル」を算出しますが、似たような考え方で、情報の損失が少ない順に「第1主成分」「第2主成分」・・・と決めていきます。
実際の計算プロセスでは、データを基準化してから相関行列を計算して、さらに相関行列の固有値と固有ベクトルを計算しますが。ここでは詳細なプロセスは割愛します。詳しい計算プロセスを知りたい方は、以下の専門ページもご参考にしてください。
(参考URL:http://www.statistics.co.jp/reference/software_R/statR_9_principal.pdf)
理論上、主成分の数は変数(データ項目)の数だけ定義できます。何番目までの主成分を採用するかは、後で紹介する「寄与率」を基準に判断します。
つぎに、主成分分析のアウトプットを見てみましょう。
各主成分に特有の情報としては、固有値と寄与率、主成分負荷量が与えられます。
固有値は各主成分の分散に対応しており、主成分が保持している情報の大きさを示しています。寄与率は、各主成分が持っている情報の大きさを比率(%)で示したものです。下表の例だと、第1主成分はデータ全体の情報のうち57%を説明できていることになります(逆に言うと43%の情報は損失している)。第2主成分まで組み合わせて見ることで、76%の情報をカバーすることができるわけです。
明確な決まりではありませんが、通常は「固有値が1以上」または「累積寄与率が80%以上」までの主成分を採用し、それぞれを組み合わせて結果を解釈します。

(表1 主成分分析のアウトプットの例)
主成分負荷量(因子負荷量)は、各変数に対して係数として与えられるもので、上述の固有ベクトルから計算されています。
この数値が大きいほど、各変数が主成分に与える影響力が大きくなります。
重回帰分析の係数に似ており、個々のデータ(素点)を代入することで、主成分得点が得られます。
主成分得点は通常、下図のように複数の主成分を組み合わせた散布図として図示して解釈します。各データの位置関係を見ることで、それぞれのデータの特徴がはっきりするからです。
また、クラスター分析と同様に、それぞれの主成分が持つ意味を解釈する部分は、分析者に委ねられています。多くの場合、第1主成分は総合力を示す指標になりますが、第2主成分以降がどのような意味を持つのか、また、その意味を表現する適切な名称については、解釈する人によって変わってきます。
ここは、分析者の腕の見せ所と言えます。
(図2 2つの主成分をクロスしてみる例)
■ビジネスへの応用例
やや抽象的な説明が続いたので、実際の応用例を見ていきたいと思います。
主成分分析の応用例として一般的なのは、アンケートデータの分析です。被験者にたくさんの質問項目に答えてもらった上で、それらを縮約することで、たとえば総合的な商品力を比較したりします。
有名な事例は、次のような飲料のポジショニングに関する分析です。
(図3 飲料のポジショニングに関する分析)
商品サンプルをモニター(被験者)に実際に飲み比べしてもらい、それぞれの印象を「キレのある感じ」「気分が落ち着く感じ」といった評価軸について、それぞれ5段階程度で評価してもらうのが一般的です。「XXXな感じ」はいくつ設定して構いませんが、人間の印象を(ある程度)数値化できることがポイントです。
このアンケート結果をもとに主成分分析を行うと、上記のような商品マップが作れます。商品マップは、そのまま市場における商品イメージのポジショニングを表現していますので、マーケティングの領域ではとても重要な情報になります。抽出された主成分が、これまでにない面白い切り口であれば、なおさらでしょう。
では、上記の例では、どのように解釈するのでしょうか。
第1主成分は「総合的なおいしさ」であり、どのような飲料であれ、とにかく美味しいと感じてもらえたかどうかを示しています。商品力として、とても重要な指標です。
第2主成分はもう少し具体的な指標で、主成分得点が高い飲料に炭酸系飲料が多いことから「清涼感」を示していると言えそうです。右上の領域に位置づく商品は、飲んだ後に強い清涼感が残り、かつ、美味しいと評価されているわけです。
この商品マップを参考に、たとえば自社の新製品に近いポジションにいる(=競合になり得る)商品を確認し、売り場の陳列で近い位置に置いてもらうなどのアクションが検討できます。
新商品を開発する際のヒントも得られるでしょう。そもそも、第1主成分の得点が低い(=美味しくないという印象を持たれている)ようでは、販促を考える以前に商品の味の見直しが必要です。その際、ベンチマークになる他社製品も検討できます。
もちろん、いつもこの例のように解釈しやすい分析結果になるわけではありません。
第1主成分と第3主成分、第4主成分を組み合わせた商品マップが有効なケースもあります。必ずしも累積寄与率だけで軸を決められないのが、主成分分析の解釈を難しくしている1つの要因でもあります。
クラスター分析同様、結果の解釈には職人的な要素が含まれてくるため、試行錯誤しながら決めていくことになります。
以上で、第4回目を終了します。
次回は、時系列データの分析手法をご紹介したいと思います。
【関連記事】 「使ってみたくなる統計」シリーズ
第1回:相関分析
https://bdm.dga.co.jp/?p=1254
more
2017/07/06

2016/10/11

2016/08/04
more

2019/12/17

2018/08/17
more

2015/05/08

2014/11/06

2014/07/17
more
more

2018/07/04

2017/10/03
")
2017/03/30










![地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]](https://bdm.dga.co.jp/wp-content/uploads/2016/09/e9f52ed185c3179f4e6674d9459ffb02-250x150.jpg "地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]")






とは何か?")
をマーケティングに活かす! 〜AIは「読者の心をつかむ画像」を選定できるのか?〜")
をマーケティングに活かす! 〜AIでレコメンデーション・エンジンは賢くなるのか?〜")