




での訪日外国人の分析 ~長野県を題材に~")

2017/07/06
![]()

こんにちは。ビッグデータマガジンの廣野です。
「使ってみたくなる統計」シリーズ、第2回目はアソシエーション分析です。
前回も名前だけは登場していましたが、念のため前回の話をおさらいすると、相関(英語ではcorrelation)ではなく、「商品Aを買っている人の65%が商品Bも買っている」という関連(英語ではassociation)を分析する手法です。
データマイニングの代表的な手法で、他にも「マーケット・バスケット分析」と呼ばれたりもしますが、ここで言う「バスケット」とは買い物カゴを意味しています。Amazon.comのようなECサイトで“買い物かご(バスケット)に入れた”ときのログデータを分析することから、このような名前で呼ばれることがあります。
ビッグデータの利活用で「データ間の相関関係を発見する」と言うとき、このアソシエーション分析を指していることが多いようです。良く知られた分析手法ではあるものの、相関係数のようにエクセルで簡単に計算できるわけではないので、実際にどんなアウトプットが出てくるのか知らない人も多いのではないでしょうか。
どんなことをやっているのか、この機会に知っていただければと思います。
■そもそもアソシエーション分析とは?
アソシエーション分析は近年になって開発された分析手法で、1994年にR. Agrawal氏らが発表した論文「Fast algorithms for mining association rules」(IBM Almaden Research Center)が始まり言われています(もちろん、諸説あります)。
この論文で紹介されたアプリオリ(Apriori)アルゴリズムは、現在でもアソシエーション分析の原型として幅広く応用されています。今後、本記事で特にことわりなく「アソシエーション分析」という言葉を使ったら、それはアプリオリ・アルゴリズムを使っているとご理解ください。
アソシエーション分析は、もともとは店舗のPOS(point of sales)データの分析のために開発された手法で、膨大なログデータの中から意味のある関連性を抽出するために開発されました。POSデータは通常「トランザクション形式」と呼ばれるデータですが、定量的なデータではないため、このままでは前回ご紹介した【相関係数】を計算することができません。そこで、別アプローチの分析方法が生み出されたわけです。
「トランザクション形式」についてはイメージが湧かないと思いますので、本題に入る前に少し触れておきましょう。
次の表は、トランザクション形式のデータの一例です。

表1 トランザクション形式のデータの例
IDとは通し番号で、店頭における顧客の数に該当します。ユニーク数ではなく、ただの記録された順番を管理するための通し番号です。項目(アイテム)は、その顧客がどんな商品を購入したかを示しています。これは最もシンプルな例ですが、実際はこのデータに日付・時刻や大まかな属性情報(性別、年代、ポイントカードのIDなど)が含まれます。
ご覧になってわかる通り、定性的なデータである上、エクセルで言うところの「1つのセル」に含まれる項目数が一定ではありません。このままだと「記録が全部でいくつあるか(IDの個数)」は集計できても、「項目そのものがいくつあるか」「各項目はどれくらい記録されているか」は集計できません。そもそも数量的なデータではないので、四則演算もできません。エクセル等でデータを集計・分析するには、たいへん不向きなデータなのです。
もちろん、トランザクション形式の利点もあります。それはデータの“軽さ”です。
データが軽いと言うことは、同じ情報量を少ない容量に圧縮して保存できるため、より多くのデータを貯めておくことができます。
たとえば、表1のデータをエクセル等で集計できる形に変換する方法として、次の例(表2)があります。
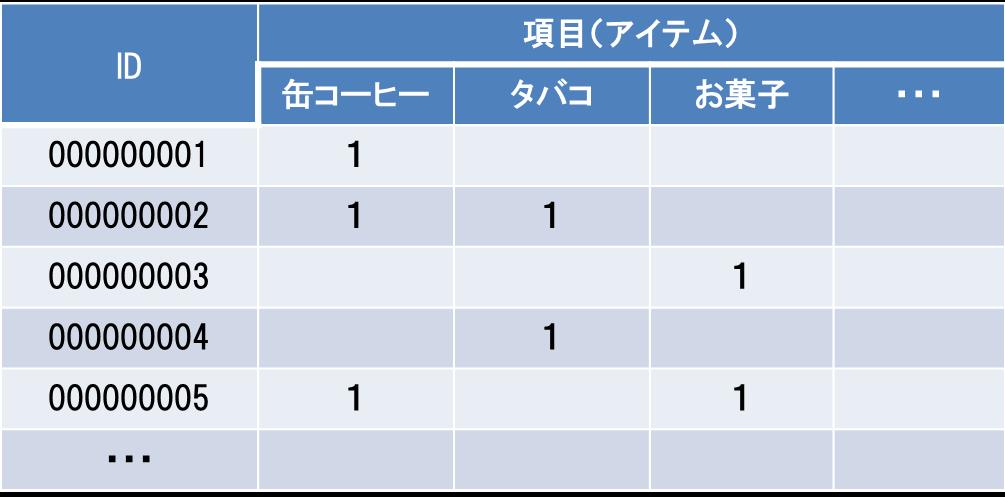
表2 マトリックス形式のデータの例
これならピボットテーブル等で集計できそうですが、新しい項目が増えた時に列方向が無尽蔵に追加されてしまうので、データの持ち方としては非効率です。このような「マトリックス形式」のデータは項目が増えると、あっという間に巨大な容量になります。POSデータのように、毎日大量に発生するデータを全て保存したい場合には、トランザクション形式の方が有利なことが分かります。
さて、話をアソシエーション分析に戻しましょう。
四則演算すらできないトランザクション形式のデータの中から、データ間の関連性を見つけてくるためには、相関係数とは全く異なるアプローチが必要になります。
相関係数であれば「変数Aと変数Bの相関係数は0.67」というように表現できましたが、アソシエーション分析では「Aという条件の時にBが起こる。その確率は・・・」という表現になります。これをアソシエーション・ルールと呼びます。
通常「{A}⇒{B}」という表記をしますが、左辺を条件部(left-hand-side:LHS)、右辺を結論部(right-hand-side:RHS)と呼びます。
アソシエーション分析の結果について、解釈の仕方を見ていきましょう。(表3)
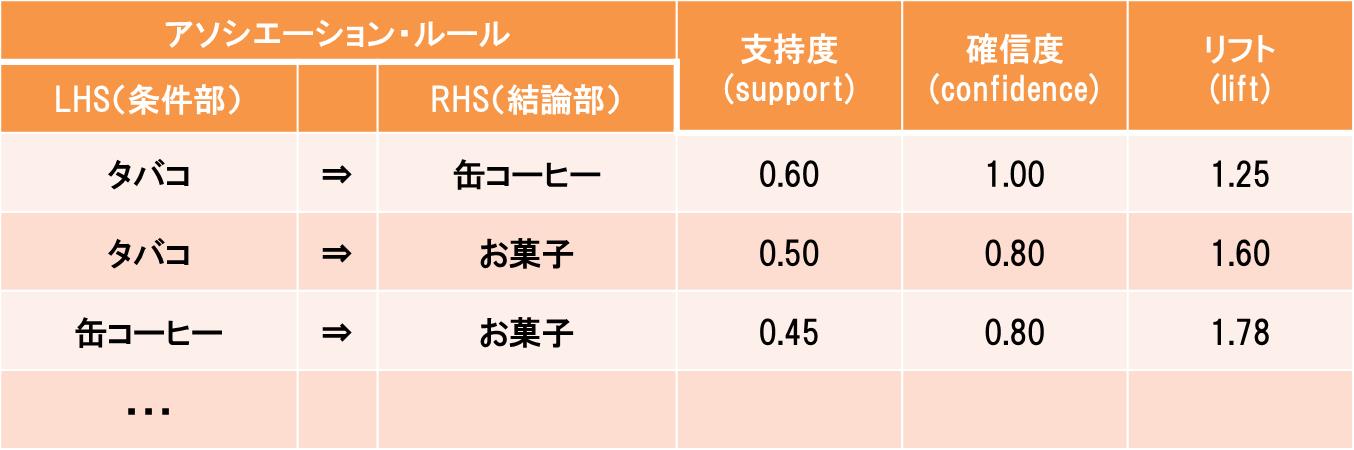
表3 アソシエーション分析の結果の例
まず、アソシエーション・ルールは、必ずしも1項目どうしのルールに限りません。たとえば「タバコと缶コーヒーを買っている人は、一緒に雑誌を買っている({AかつB}⇒{C})」というルールもあります。これは、1対1の関係を見る相関係数とは大きく異なる点です。
相関係数との違いをもう一つ挙げると、アソシエーション・ルールには“方向”があるということです。相関係数であれば、2つの変数間の相関係数は一定です。しかし、アソシエーション分析の場合は「{A}⇒{B}」の場合と「{B}⇒{A}」の場合では、結果が異なります。どちらを起点(条件部)にするかで、関連する項目が変わってくるのです。
次に、抽出されたルールを評価するための指標が3つありますので、1つずつ意味と解釈の仕方を見ていきましょう。
①支持度(support)
全データの中で、「商品Aを買う時に、商品Bも一緒に買う」({A}⇒{B})というルールが出現する割合です。この指標が大きいほど、全体の中でそのルール(Aを買ったらBも買うという組み合わせ)が出現する割合が高くなります。逆に小さいと、それは滅多に起こらない出来事なので、ビジネスとしてはあまり旨味がないルールとも言えます。
計算方法は、次の通りです。

式が意味する内容は、非常にシンプルですね。計算式がシンプルということは、データ容量が大きくなっても計算速度が速いことを意味しますので、ビッグデータを分析する際のメリットは大きくなります。
②確信度(confidence)
信頼度とも呼びます。条件部(A)の項目が出現する割合の中で、条件部(A)と結論部(B)が同時に出現する割合です。この指標が大きいほど「商品Aを買う時に、商品Bも一緒に買う」割合が高いので、A,Bという2つの商品(項目)は関連が強いということになります。このため、相関係数に近い意味を持つ指標とも言えます。
計算方法は、次の通りです。

A,Bという2つの項目の関連性は確信度で把握できますが、解釈には注意が必要です。
たとえば、そもそも商品Bが購入される割合が全体の90%程度だった場合(ほとんどの顧客が商品Bを購入している)、必然的に他のほとんどの商品と関連性があることになり、併売を促すための有益な情報とは言えません。
一方、商品Bが購入される割合が全体の20%程度だった場合、たとえ確信度が大きくなかったとしても、それは商品Aの販促に活かせる有益な情報となり得ます(意外な組み合わせとして)。
このように、単純に確信度だけを見て関連性の有無を解釈するのは危険であり、次のリフト値が重要な指標になります。
③リフト値(lift)
リフト値とは、商品A(前提部)と一緒に商品B(結論部)も購入した人の割合は、全てのデータの中で商品Bを購入した人の割合よりどれだけ多いかを倍率で示したものです。
計算方法は、次の通りです。

リフト値が低ければ、商品Bは単独(の理由)で売れており、商品Aの商品との関連性よりも商品B特有の理由で売れていると考えられます。つまり、商品Aと商品Bの確信度が高かったとしても、その関連性は怪しい(あまり意味が無い)という解釈になります。
一般的な目安として、リフト値が1より大きい場合は有効なルールとされています。
以上から分かるように、抽出されたアソシエーション・ルールが全て有益な示唆になる訳ではなく、3つの指標を相互に確認しながら判断します。また、当然ですが、そのルールが分析の目的に合致しているか、現場で再現させることが可能かどうかも考慮して、最終的にいくつかのルールを採用します。
元のデータ量にも依存しますが、アソシエーション・ルールが数千も抽出されることだってあるため、ベテランの経験値や現場感だけでは思いもよらなかった関連性が見つかる可能性があります。ビッグデータの時代になり、アソシエーション分析が注目されている理由がよくわかります。
アソシエーション分析の解説は以上ですが、具体的な分析の手順については本稿で詳しくは触れません。もっともお手軽に試せる方法は、R言語の「arules」パッケージが無料で活用できるので便利です。チャレンジしてみたい方は、「データマイニング+WEB@東京」を主宰するデータサイエンティスト・濱田晃一さんのスライドを参考にしてみてください。
(参考URL:http://sssslide.com/www.slideshare.net/hamadakoichi/r-r-4219052)
■ビジネスへの応用例
アソシエーション分析の応用範囲は非常に広いのですが、何といっても有名なのが“紙おむつとビール”でしょう。
米国の大手スーパーマーケットでPOSデータを分析した結果、紙おむつとビールが一緒に買われていることが分かった。検証の結果、父親が子供の紙おむつを買いに来たついでに、缶ビールも購入していることが分かった。そこで、この2つを並べて陳列したところ、売り上げが上昇した・・・
データマイニングという言葉をおおいに流行らせたストーリーですが、出典は「ウォール・ストリート・ジャーナルで記事として紹介されたのが最初」「ウォルマートで実際にあった事例である」など諸説あって、どうも真偽は怪しいようです。現在、このストーリー自体は、データマイニングのセクシーさ(魅力)を端的に表わす都市伝説となっています。
都市伝説ではありますが、ここで紹介されている「ユニークな関連性に基づく併売の促進」のセクシーさは、ビッグデータの時代になっても変わりません。事例はたくさんあるのですが、代表的なものを3つご紹介します。
ご自身の業務に近い事例があったら、ぜひGoogle先生でもっと調べてみてください。
①営業活動の効率化
「売上=客数×客単価×購買頻度」なので、それぞれを向上させるために訪問頻度を増やしたり、値引きの裁量幅を拡げたりといった様々なアクションが考えられます。最終的に予算達成できたからといって、それぞれのアクションがどのくらい結果(受注)に結びついたのかを検証しないでいると、効率的な営業活動が組織に定着しません。アソシエーション分析で売上と関連性の高いアクションが明確になりますが、同時に外部環境(競合の値下げや、ときには天気など!)の要素も含めて分析するのが一般的です。
②ECサイトにおける広告の最適化(リコメンド)
Amazon.co.jpで「この商品を買った人はこんな商品も買っています」というメッセージは、あまりにも有名ですね。大手のECサイトでは既に実装されているので、皆さんも良く目にすると思います。閲覧しているユーザーごとに表示する広告を変えるのが一般的なやり方で、機械学習を応用した“協調フィルタリング”と呼ばれる手法も存在します。広告の費用対効果を向上させる(クリック数や購買数を増やす)ことが主な目的です。
③ソフトウェア開発プロジェクトにおける障害対応
これは、意外な使われ方かもしれません。過去のプロジェクトで発生した事故について「発生工程」「エラー分類」「発生時の試験項目」などのログをとっておき、アソシエーション分析で事故が併発しやすい工程(ルール)を発見します。今後のリスクが可視化できるため、プロジェクト・マネジメントに役立てることができます。
以上で、第2回目を終了したいと思います。
次回は、クラスター分析についてご紹介します。
more
2017/07/06

2016/10/11

2016/08/04
more

2019/12/17

2018/08/17
more

2015/05/08

2014/11/06

2014/07/17
more
more

2018/07/04

2017/10/03
")
2017/03/30










![地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]](https://bdm.dga.co.jp/wp-content/uploads/2016/09/e9f52ed185c3179f4e6674d9459ffb02-250x150.jpg "地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]")






とは何か?")
をマーケティングに活かす! 〜AIは「読者の心をつかむ画像」を選定できるのか?〜")
をマーケティングに活かす! 〜AIでレコメンデーション・エンジンは賢くなるのか?〜")