










2017/07/06
![]()
<はじめに>
ビッグデータ活用環境の進展によって新たに実用可能になった、人間の知性に近づこうとしているAI(人工知能)ですが、本当の人間のような対応を実現するというビジョンには、まだまだ遠いのも現実です。そういった中、実際にビジネス活用されている現場ではどのような工夫をしているのか?について、澪標アナリティクス株式会社さまにご協力いただき、解説いたします。

(澪標アナリティクス代表の井原さん)
今回はチャットボットを取り上げます。
ご承知の通り、「チャットボット」の活用はブーム(流行)になっていると言えます。多くのサービスリリース情報が発信されていますね。

(Googleで「チャットボット」をニュース検索した結果:2017/05/19現在)
SiriやAmazon Echo、Googleアシスタントなども良く活用されていて、一般人はまるで普通の人間と会話するようなレベルのチャットボットが登場するのでは?と思い始めています。

ところが、これは大きな誤解です。
<② チャットボットの技術的な課題>
現在の技術では、「ひとつの自然文」を理解することはできるのですが、「前後の文脈を理解できない、文脈を覚えていられない」のです。

さかのぼるべき範囲のデータを保持しておいて分析すればよい。と考える方もいるでしょうが、その範囲の決定も簡単ではないですし、さかのぼる範囲が少し増えるだけで、対象となる複数の「自然文」に対する分析パターンが膨大になってしまうのです。このような環境下で、さかのぼる可能性があるデータを全て保持した上で、これを対象にしてリアルタイム分析するなんて無理なのです。

また、日本語は英語に比べるとファジーな言語です。にもかかわらず、英語圏の研究投資に比べると日本語圏の研究投資金額は小さく、結果的に実現の見込みも立っていないのです。
もう一点、AIに学習させるデータにも課題があるようです。膨大な学習データがあればあるほどAIは賢くなるはずなのですが、この学習データが誤っていると、AIは誤った知恵を持ってしまうのです。すなわち、教師がアホだとAIはアホになるのです。
一方で、まともな教師データを生成するのに沢山の工数をかけていては、投資が膨大になってしまいます。よって、現在は自然文を理解した後の処理がルールベースでの回答だったり、単なる検索だったり、従来型のレコメンデーションだったりしているのです。
結論ですが、専門家曰く
「日本語で、人間らしい会話はできない。」
「英語でさえ、いくらを投資すれば、いつ、どのレベルまでできそうか?の目処が立っていない。」
とのことです。
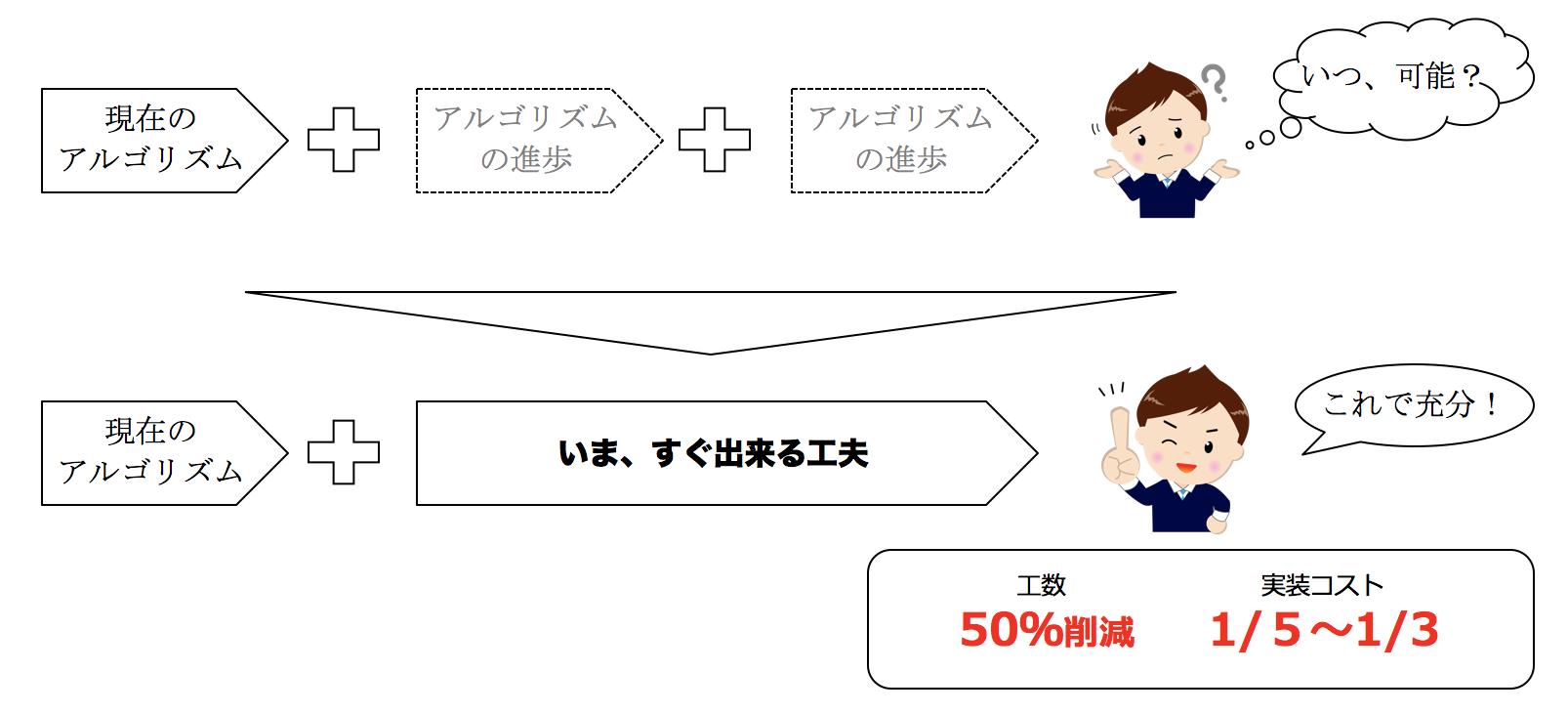
<③ AI活用のアプローチは、アルゴリズムの進歩だけではない?>
AIの専門家は、ついつい「データを増やして学習させよう」とか「他のアルゴリズムで試そう」とか「他のアルゴリズムを組み合わせよう」という、アルゴリズムを高度化するアプローチを検討しがちです。自分が専門の分野に拘ってしまうのです。
しかし、本当に顧客志向、現実志向で、結果にコミットする仕事集団なら、違った観点も検討します。今回は「UIデザイン」で解決した例を挙げてみたいと思います。アナリストがデザイナーの手を借りたのです。

<④ Watsonサミット2017のユーザー会で公開された事例>
チャットボットの課題である、「前後の文脈を勘案できない」という課題と「適切な教師データを与えるのに手間がかかる」という2つの課題を、『検索風デザイン』と『“いいね”スタンプの配置』で解決しました。

(澪標アナリティクスの報告事例)
チャットボットへの問いかけを検索窓への入力を通じてユーザーにさせることで、検索になれたユーザーは、自分が知りたいコンテキストを「複数のキーワードを入力する」という行為で実施したのです。すなわち、「検索風UI」は文脈を入力させる魔法のデザインだったのです。

また、自分のポジティブな気持ちを“いいね”スタンプで表現することに慣れたユーザーは、ユーザー自身で適切な教師データを選んだのです。提示された回答情報が適切ならば“いいね”スタンプが押せるUIは、適切な教師データを見つけるための魔法のデザインだったのです。

<⑤ 期待できる成果>
特に、大量の資料を保管したり、大量に発行されるドキュメントの中から顧客に資料を提示したりする仕事が多い公共団体や金融機関では、仕事時間の多くが“資料探し”に使われているようです。この課題を流行の「AIボットで解決したい!」というニーズは多いようです。
しかし、現在の技術では<② チャットボットの技術的な課題>でお話ししたとおりの課題があります。
今回のアプローチで作られたチャットボット(見た目は資料検索サイト)は、資料探しの時間を半減させられているようです。その上、適切な教師データを抽出する工数がほとんどかからないのです。加えて、複雑なチューニングも不要らしく、チャットUIでの開発・QAのメンテナンス費用に比べると3〜5分の1のコストで実装できるようです。

ついつい、レベルの高い技術をつかった解決策を提供したくなるものですが、本気で成果にコミットするって、どんな手を使ってでも成果を上げるってことなのですね。当たり前と言えば当たり前ですが、なかなか気づかないのも現実です。
<協力者のご紹介>

澪標アナリティクス株式会社 代表取締役 井原 渉
国立九州工業大学非常勤講師
大学在学中に外資系経営コンサルティング会社(日本法人)設立
史上最年少(当時)でプライバシーマーク審査員補資格取得
老舗中堅ゲーム会社にて分析部門の立上げにリーダーとして参画し、離脱防止、課金促進、広告効果測定などのデータマイニング、分析体制構築を担当。
同時に大学の研究センターにおいてアクセスログに関するデータマイニングを研究。
その後、東証1部上場企業にてシニアコンサルタントとして、通信事業会社のゲームプラットフォーム等のデータ分析・KPI設定・分析用IT基盤構築のコンサルティング部門を立上げ、主にコンサルティングや教育研修に従事。
現在、自動車や広告業、ゲーム、動画などの分析コンサルティング業務に従事。
※講演実績
九州工業大学、関西大学、AWSソリューションDAYS、オンラインゲームカンファレンス、人工知能学会共同研究会、吹田市公益活動センター等多数
【執筆者情報】
 杉浦 治(すぎうらおさむ)
杉浦 治(すぎうらおさむ)
株式会社 学びラボ 代表取締役
一般財団法人ネットショップ能力認定機構 理事
株式会社 AppGT 顧問
2002年デジタルハリウッド株式会社取締役に就任。IT業界における経営スペシャリスト育成やネット事業者向け研修開発を行う。
2010年4月「ネットショップ能力認定機構」設立。ネットショップ運営能力を測る「ネットショップ検定」を主催。
2013年7月、プレステージ・インターナショナル(東証一部)より出資を受けて(株)AppGTを設立。コンタクトセンターに蓄積された顧客コミュニ ケーションデータを分析し、今後の主要な顧客接点となるスマートフォンの活用において、様々な研究や企画提案を行っている。
more
2017/07/06

2016/10/11

2016/08/04
more

2019/12/17

2018/08/17
more

2015/05/08

2014/11/06

2014/07/17
more
more

2018/07/04

2017/10/03
")
2017/03/30










![地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]](https://bdm.dga.co.jp/wp-content/uploads/2016/09/e9f52ed185c3179f4e6674d9459ffb02-250x150.jpg "地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]")






とは何か?")
をマーケティングに活かす! 〜AIは「読者の心をつかむ画像」を選定できるのか?〜")
をマーケティングに活かす! 〜AIでレコメンデーション・エンジンは賢くなるのか?〜")