



![地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]](https://bdm.dga.co.jp/wp-content/uploads/2016/09/e9f52ed185c3179f4e6674d9459ffb02.jpg "地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]")


2017/07/06
![]()
今回のビッグデータマガジン・インタビューは、大量データの高速処理に関する技術提供とコンサルティング、製品開発を行う「株式会社高速屋(以下高速屋)」の代表取締役社長 新庄耕太郎さまにお話をうかがってきました。
同社が提供するデータ処理エンジン“高速機関”は、高性能なサーバーを構築する必要なく汎用的なサーバー1台でビッグデータを分析でき、非常に低価格での運用ができる画期的な製品です。
また、2015年に入り、大量データをデータベース化することなく必要なデータのみを短時間で抽出できるソフトウェア“解析ブースター”の提供も開始しました。
どのような強みを持つ会社か、また、どのような製品なのか詳しく聞いてみましょう。
—御社の特徴を教えてください。

株式会社高速屋
代表取締役社長
新庄耕太郎氏
高速屋は、2002年に高速データ処理エンジンを中核事業として創業しました。
デンソーからの出資によって開発した“カーナビの目的地向け検索エンジン”は、メモリ256kbという非常に小さいメモリで、7千万件以上の複合検索と距離ソートを実現することに成功し、特許を取得しています。
また、2013年より提供開始した“カーナビ向け地図差分更新システム”では、数時間かかっていた車載機の地図更新が0分となり、大手自動車メーカーのサービスにも採用されています。
これまでハードの制約が大きかった領域での高速処理を実現してきたことで、国内では32件、米国16件等々、高速データ処理技術の特許を取得(2015年6月1日時点)し、これらの特許や技術力による技術提供、コンサルティングを強みとしています。
—技術提供以外に製品も提供されていると聞きましたが。
はい。代表的な製品は、“高速機関”と“解析ブースター”の2つです。最近、提供を開始した“解析ブースター”は、新聞でも記事になり、多数の問い合わせを頂いております。
我々が培ってきたカーナビシステム開発やサーバー向けのソフト開発における独自技術を汎用的な製品にしたことで、いままで様々な理由でデータの利活用が進まなかった企業をサポートできればと考えています。
—では、早速“高速機関”について教えてください。
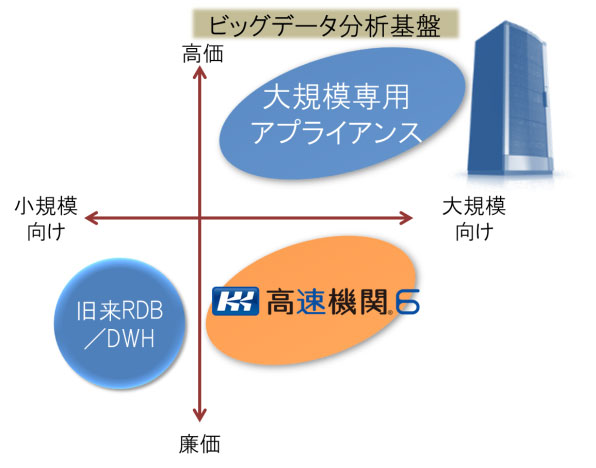
“高速機関”は、汎用サーバーに組み込み、データ処理を高速化させる製品です。
大量データ処理基盤としては、Hadoopなどのハードウェアをどんどん積んでスケールアウトし、パフォーマンスを上げることが考えられますが、“高速機関”は汎用サーバー1台での大量データ・高速処理を実現しているのが特徴です。
つまり、ハードの制約を量でカバーするのではなく、制約の中でパフォーマンスを最大化することで、廉価にビッグデータ処理を可能にしたのが高速機関です。
<高速機関の特徴>
他社データベース製品であれば、例えば構築に数千万円~1億円かかるものが、高速機関では、汎用サーバー1台分、約300万円程度で構築できる場合もあります。
また、高速機関は高速なデータローディングを得意としていますので、他社データベースよりもデータを高速に分析できるようになります。

<高速機関 分析処理時間 他社DBとの比較>
高速機関は、特許化した独自のツリーアルゴリズムと、ディスクI/Oのシーケンシャルアクセスによって、大量データの高速処理を実現しています。また、データの持ち方にも独自技術を採用し、データを辞書化するため、元データの1/2~1/3のサイズになり、これも高速化につながっています。
— “高速機関”の導入実績を教えていただけますか?
すでに、小売、医薬品、自動車部品メーカ、旅行、情報サービスなど多数の大手企業に導入されています。
たとえば、スポーツ用品専門店として国内最大であるアルペンさまでは、高速機関をPOSデータ管理で導入されています。
高速機関導入前は、全国370店舗のPOSデータを本社へ集約した場合、その内容確認に約4時間かかっていましたが、高速機関導入により10分で済むようになりました。
また、店舗サーバーと統括サーバーを15分おきに同期しており、約20万アイテムの在庫状況や販売状況がほぼリアルタイムにわかるようになり、店舗間での在庫確認の精度アップや業務分析、物流への情報提供を可能にしました。

<高速機関 アルペンさま導入事例>
—次に、“解析ブースター”について教えてください。
“解析ブースター”は、CSVやテキストファイルをデータベース化せずに、必要なデータをダイレクトに高速抽出できる解析支援ツールです。
いくらビッグデータを集計する技術が普及してきたとはいえ、まだまだビジネスの現場ではデータベース化されていないデータが多数あります。
解析ブースターは、研究開発やビジネス・アナリティクス等の業務を担当する方を対象に、これまで溜めているだけだった様々なデータをシンプルかつスマートに解析できる製品で、ITに精通してなくても使いこなせるように開発しました。
一般のビジネスパーソンでもデータ抽出できるように、GUIの操作だけでデータ抽出を可能にしています。もちろん、データベースに慣れた方にはSQLでの処理も可能です。
また、よく使われているノートPCやデスクトップPCで、数千~数億件規模のデータ抽出を高速に行える点も特徴です。
これも先ほどお話しした特許取得済みの高速ツリーアルゴリズムと、非同期I/Oによって実現しており、他社データベースとの比較ベンチマークテストでは、あるサプライヤー向け発注データ編集処理において、解析ブースターは他社データベースよりも14倍も速い結果となりました。

<処理時間のベンチマークテスト例>
価格は、エントリー版が1ユーザー24万円、スタンダード版は5ユーザーで90万円です。

<解析ブースターの価格表>
—この価格であれば導入が期待されますね。“解析ブースター”は、今後どのような利用方法があるとお考えでしょうか。
データベース化せずに、ファイル to ファイルで高速なデータ抽出を行えるので、大量データのバッチ処理や解析業務など、アイデア次第で様々な用途に適用可能だと考えています。
たとえば、ビジネス部門や研究部門で行われるデータ分析の前処理業務を高速化簡素化することができます。解析ブースターを導入すれば、データベースに格納されていない様々なデータを事前結合することや、サマリー、フィルタリングすることが可能です。現場の業務担当者が素早く、簡単にCSVファイルから必要なデータを抽出し、エクセルやBIツールと連携して解析できるようになります。

<解析ブースター活用例 エクセルや解析ツール向けのデータ抽出>
また、IoTにおける大量のデータも、一定時間/一定量毎に処理を起動するようにししておくことで、大量のセンサーデータの中から必要なデータのみを抽出できるようになります。

<解析ブースター活用例 IoTにおけるデータ整理>
また、特定の製品やサービスに組み込むことも可能ですので、ある製品のデータ処理機能を高度化し、製品を差別化することにも貢献できるでしょう。
—御社の今後の展開について教えてください。
ビッグデータを大量に蓄積したものの、分析するための前段階における処理の作業にはまだまだ時間がかかっている現場が多いと聞いています。
優秀なデータサイエンティストや現場の研究員が、その前処理に多くの時間を費やしている状況に対して、我々の“高速機関”や“解析ブースター”がその時間を大幅に削減することで貢献できます。そして、その削減できた時間でデータサイエンティストが、分析やビジネスにおける示唆の抽出、さらには現場での行動に時間を費やし、本当の成果につなげられるように支援していきたいと考えています。
【インタビュー後記】
技術の発展によって、大量のデータを低価格で分析できるようになったとはいえ、まだまだビジネスの現場で気軽に使えるとは言い難いと感じています。
高速屋は、独自の特許や様々な技術を用いて製品化に踏み切り、ビッグデータにまつわる現場と技術のギャップを埋めるための挑戦を続けています。
ビッグデータ技術やBI製品が海外から数多く出てきています。
一方で、国産製品でいえばJubatus、国産企業ではウイングアーク1st社など、個性的な製品や企業も存在感を示しています。さらに日本人技術者でいえば、シリコンバレーで起業したトレジャーデータやFlydataなどもあります。
ビッグデータ市場における、Made in JapanやMade by Japaneseの今後の活躍に期待が寄せられます。
【執筆者情報】
 土本 寛子(つちもと ひろこ)
土本 寛子(つちもと ひろこ)
ビッグデータマガジン副編集長
【経歴】モノづくりに興味を抱き、製造業向けシステム開発プログラマー、SE、業務およびシステム導入コンサルタントとして従事。また、ナレッジマネジメントやWebデザイン開発などにも関与。
現在はビッグデータマガジンを運営。
more
2017/07/06

2016/10/11

2016/08/04
more

2019/12/17

2018/08/17
more

2015/05/08

2014/11/06

2014/07/17
more
more

2018/07/04

2017/10/03
")
2017/03/30










![地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]](https://bdm.dga.co.jp/wp-content/uploads/2016/09/e9f52ed185c3179f4e6674d9459ffb02-250x150.jpg "地方自治体で広がるデータ活用・データ分析の取り組み [2016年11月26日(土)オープンガバメント推進協議会公開シンポジウム]")






とは何か?")
をマーケティングに活かす! 〜AIは「読者の心をつかむ画像」を選定できるのか?〜")
をマーケティングに活かす! 〜AIでレコメンデーション・エンジンは賢くなるのか?〜")